Big Data Generation for Diabetes and Disease Prediction
Problem Statement
With health concerns arising in every aspects of our daily lives, it is natural to look out for potential possibilities of getting certain diseases when you age. One of those diseases, that could also be lethal, is diabetes. Those of Asian descent are at higher risk of developing type 2 diabetes even when taking into consideration of the average lower BMI (Chan JC, Malik V, Jia W, et al.). There are many studies done investigating the cause of this phenomenon of disproportionality and many factors contributing to this issue has been identified. With that, we have decided to model after medical health records and diagnosing “patients” as high or low risk individuals through regression and classification methods in an effort to simulate a common procedure hospitals will be responsible for.
Tech Stack
- Data Generation is done using Python’s Pandas, Numpy and Scipy libraries and exported as numerous CSV files to simulate a patient having taken different physicals having different medical reports to go off of.
- Data Processing is done using Scala with Apache Spark SQL and methods from Apache Spark’s ML library
- Models are built entirely with Scala while using Apache Spark’s ML library Graphics of the data distributions are done in Python using Matplotlib and Seaborn libraries
Outcome Function Definition
- We highly correlated the outcome function with glucose, insulin and weight.
- We added random noise to each feature, as well as to the cumulative aggregation of the three.
- We then probailitiically assigned the correct outcome 90% of the times, ie, 10% noise was assigned at outcome assignment as well
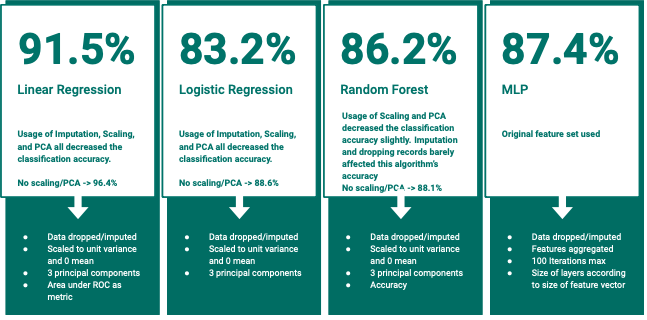
More information on data analysis and code can be found here