Vision Transformers on Chest Xray
Problem Statement
The availability of datasets in healthcare is limited. We are interested in exploring how vision-transformers pre-trained on generic, non-healthcare data perform on highly specialized datasets like chest X-Ray images. We plan to compare the performance of vision transformers with supervised pre-training, self-supervised pre-training and no pre-training with our baseline model. Experimental implementations can be found here
We use Vision Transformers in three different setups
- Vision Transformers pretrained on ImageNet
- Vision Transformeres pretrained using Supervised Learning
- Vision Transforrmers without any pretraining
Dataset
We will be using the National Institutes of Health Chest X-Ray Dataset (link) which comprises of 112,120 X-ray images of size 1024 x 1024 with disease labels from 30,805 unique patients.There are 15 classes (14 diseases, and one for “No findings”). Images can be classified as “No findings” or one or more disease classes. The labels were created using Natural Language Processing to text-mine disease classifications from the associated radiological reports. The original dataset size is ~45 GB. However, considering the project time and resource availability, we will be using a smaller sample to the data set.
Results
| Model | Validation Accuracy | Testing Accuracy |
|---|---|---|
| VGG16 | 45% | 43% |
| Resnet | 45% | 46.2% |
| Vision Transformer Pretrained on ImageNet | 45.3% | 44.2% |
| Vision Transformer Pretrained using Supervised Learning | 46.5% | 48.7% |
| Vision Transformer Without Pretraining | 45.33% | 43.33% |
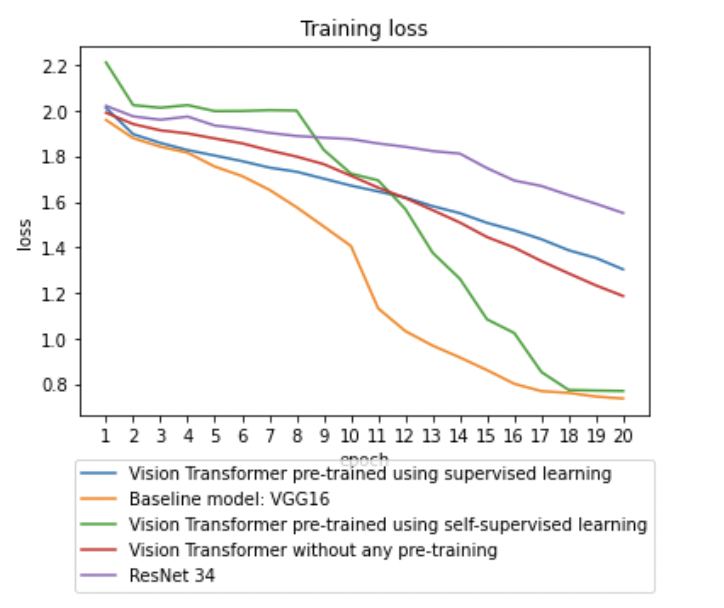
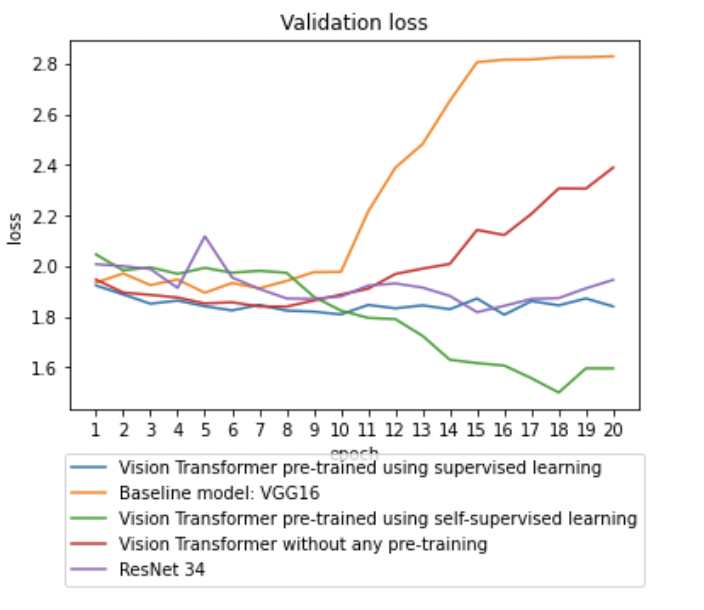
Conclusion
Pre-trained vision transformers have shown promising results when fine-tuned with small-medium sized datasets. Vision Transformer attains excellent results when pre-trained at sufficient scale and transferred to tasks with fewer datapoints. The key idea is increase test accuracy with small sizes of fine-tuning datasets. Based on our experiments, we can conclude that vision transformers have immense potential to achieve this. Further experiments need to be performed to solidify our results. Similar surveys can be done with larger samples of this dataset. Models pretrained on different sizes and different kinds of data, especially medical images should be explored.
Detailed Report can be found here